











最近又被GPT-4的巨瓜给吃撑了。相信大家都关注到了,GPT-4的很多内部信息被扒到了网络上,让OpenAI彻底Open了。根据各路大神们追本溯源的结果看,这次的爆料内容可信度很高,所以我们也就基于这次爆料,来聊聊大模型LLM。

爆料内容很多,在这里只提炼几个值得关注的点。
GPT-4将被超越
在爆料的这位老哥看来,OpenAI之所以不Open,不是怕将来人类会被AI所毁灭,而是因为他们做的事情没有护城河。他甚至认为未来所有中美的互联网大厂或者AI初创企业,都有能力构建出和GPT-4一样,甚至性能超过GPT-4的模型。
为了掌握LLM的技术和市场先机,各大公司在没爆料之前,“千模大战”早已打响,每家企业都在加紧布局大模型的开发和部署。他们不惜投入巨资,购买显卡、服务器等硬件设备,还招聘人工智能、机器学习、自然语言处理等领域的专业人才,建立ML infra和LLM ops等基础设施和运维体系。各个都在摩拳擦掌,想要大干特干一场,GPT-4信息泄露之后,这正是抄作业的好时机。但有一个关键因素被很多企业忽视了,那就是数据!至于为什么,我们结合后面爆料的数据再来分析。
模型参数
GPT-4模型的参数是GPT-3.5的10倍,达到了惊人的1.8万亿的参数,这意味着GPT-4的数据已经和我们人类大脑的神经元的数据是同一个量级了。所以有人说GPT-4的智力水平,已经达到了一个斯坦福学生的水平,这么看来,一点也不为过。
数据集成
GPT-4是在约13万亿的tokens上进行训练的,相当于6万亿的文字。拥有来自外部训练数据服务商和内部私有的数百万行指令微调数据,但可惜爆料老哥并没有找到太多关于他们强化学习的数据,但这也从侧面反应出,数据对于一家企业来说至关重要,而数据又是LLM的灵魂,没有高质量、高覆盖、多样化的数据,就无法训练出强大的LLM。这也是上文提到的,很多企业想做大模型,万事俱备,只欠数据。
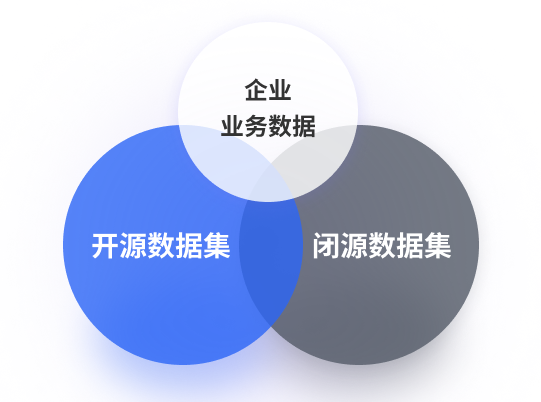
因为训练LLM不仅要有开源的公共数据,更要有闭源的企业内部私有知识库,才能让LLM进行有效的微调和满足不同行业和场景的定制化需求。拿爆料者给的信息来看,GPT-4 它不是1个模型,而是由16个小模型组成的,这16个小模型就像是不同领域的专家,比如有精通历史的,有精通科技的,当然肯定也要有精通垂直行业的私有知识库内容的,这样才能满足企业不同应用场景的需求。所以,模型性能想要得到突破,尤其是垂直领域大模型,重点在于数据质量和多样性的提升。
数据是LLM训练的核心
数据是LLM训练过程中的核心要素,没有数据,就没有大模型。但是,问题又来了!获取、处理、使用数据并不容易,它涉及到很多挑战和难题。例如,如何保证数据的安全、版权、隐私等合规性?如何对数据进行有效的清洗、标注、管理等操作?如何根据不同的任务和领域选择或生成合适的数据?
倍赛科技作为行业领先的大模型数据服务商,拥有多年丰富且专业的数据服务经验,现已积累200TB的开源数据集,相当于4000万本书籍的信息量,拥有100多个多模态数据集,涵盖了文本、语音、图像、视频及点云等多种数据类型,还有数万条以上的SFT指令集,超过10亿的tokens,RLHF记录已达300万条以上,以及超过500万册的图书蒸馏数据集。所以,我们就以倍赛科技的LLM数据解决方案为例,来看看企业要如何高效而智能地处理数据问题。

RLHF
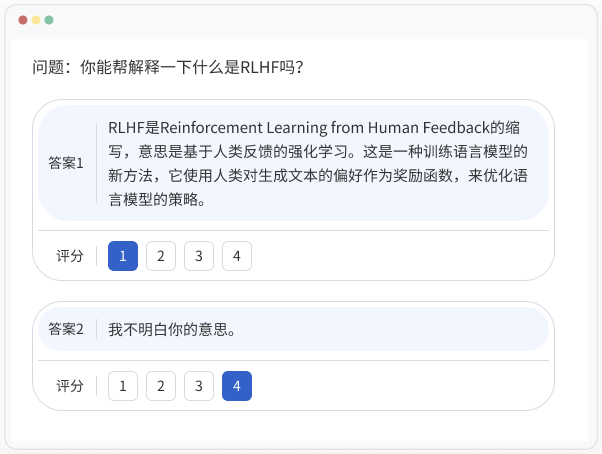
采用基于人类反馈机制的强化学习方法来训练模型,就像给机器这个“学生”找个优秀的“人类老师”,把机器学习原本的“填鸭式教学”升级到“答疑式教学”,来迅速提升他的学习成绩。也就是说,当生成式AI产生出内容后,人类老师根据自身Know-How来给结果打分,帮助模型对齐人类意图。
思维链构建
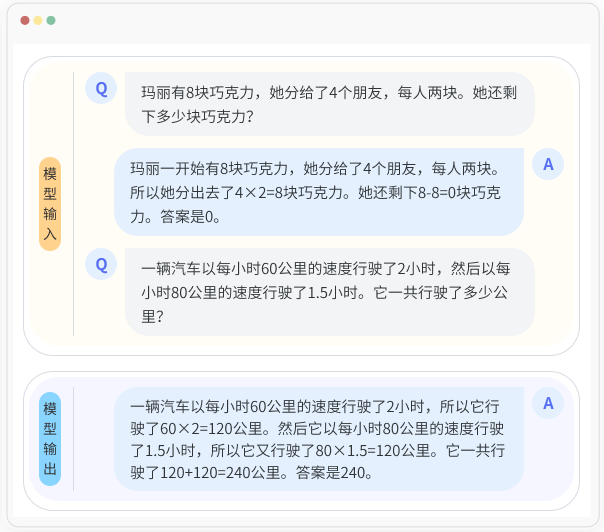
思维链构建是一种利用LLM进行推理的方法,它通过在输入中添加一些中间步骤来引导模型分解复杂的问题,并提供一个可解释的思考过程。以此来提高大模型的推理能力。
多轮对话评估
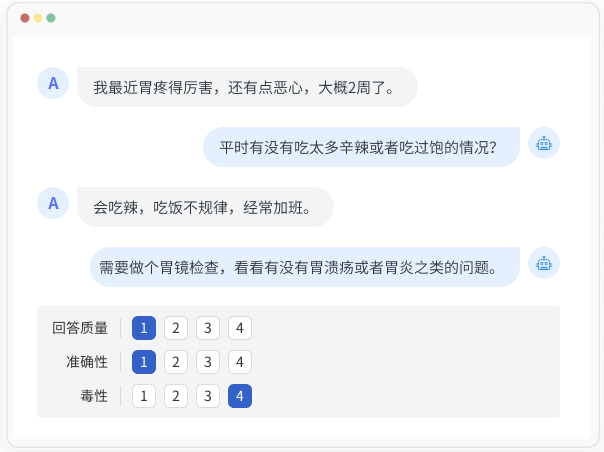
根据不同的应用场景和任务,采用不同的评估方法和指标,对智能对话系统的持续对话能力进行评价,用以检验智能对话系统是否能帮助用户完成信息或服务的获取,解决用户问题。
模型调优

人需要不断地学习和成长,更何况大模型了。如果考试结果出来,成绩不够理想,那就要反思哪里做的不对,哪里需要提升,这查缺补漏的行为,就是对模型进行评估和微调的过程,来不断优化提升模型的性能和效果。
多模态标注
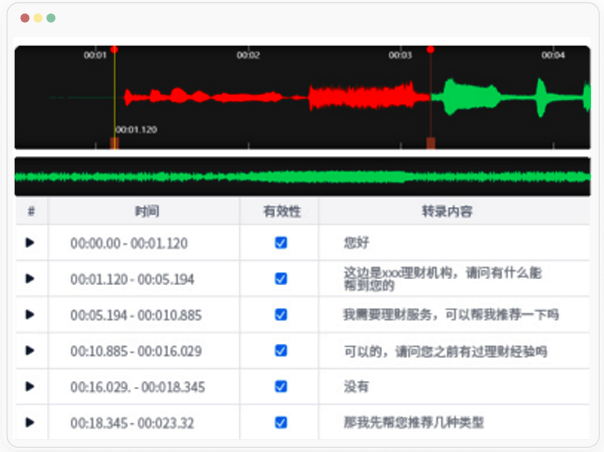
未来大模型将趋于多模态,从GPT-3的文本数据,到GPT-4文本加图片的多模态数据,再到下一代模型GPT-5,很可能将是文本、图片加音频甚至视频的数据汇合。所以数据标注工具平台也必须支持多模态的数据标注任务。
信息提取
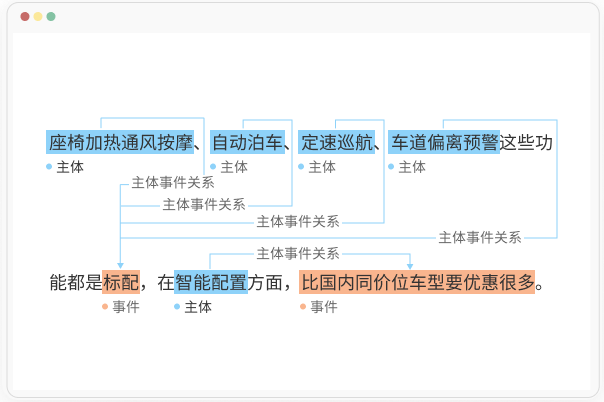
从非结构化或半结构化的文本中抽取出有意义的结构化信息,如实体、属性、关系、事件等。目的是让本文转换为易于存储、查询和分析的格式,挖掘文本中隐含的知识和规律。
数据清洗
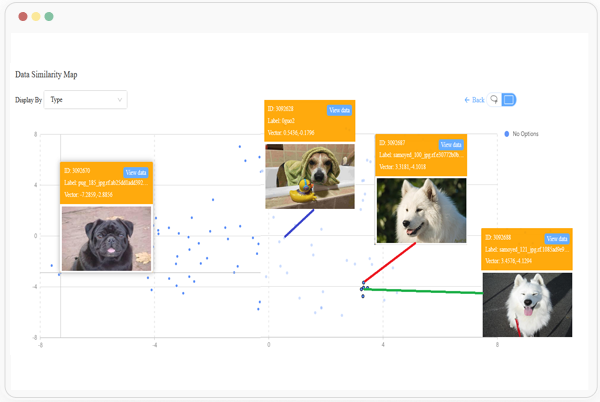
通过合规渠道采集或收集来的原始数据,都需要进行预处理,不是什么数据都能直接用的,如果不先加以处理,加入了大量低质量数据,这对模型训练没有一点好处。所以需要去除一些无效、错误、重复的数据,过滤掉隐私或者有害信息,目的是为了提高数据的质量和可用性。而且对数据清洗的要求也会越来越高,例如对数据中的污点定义和区分,往往很多的专业数据,需要数学、社会学、心理学等多个交叉领域的专业人士介入,在专业知识和经验的积累基础上,进行数据的清洗。
建立数据壁垒
回到这次GPT-4信息泄露这件事来,其实OpenAI 深知自己没有护城河,那这次爆料会不会是他们的一次自刀式的玩法呢?为的就是让新玩家先走一遍自己的路,好争取更多的时间对基于多模态数据的GPT-5完成技术攻关和高质量的数据训练与模型调优。即便其他公司超越了GPT-4,OpenAI依旧可以稳坐钓鱼台。你细品!
归根结底,大模型发展到如今令人惊叹的程度,得益于背后的海量数据和蕴含了丰富的“人类”知识,而且每一次大模型能力的提升,也都和训练数据的数量、质量和类型等多方因素密切相关。从这个角度来看,数据已成为大模型真正的壁垒。

我们会发现,大模型本身泛化能力差主要受限于数据,主要表现在,通用大模型对于任意领域的提问,模型都能很好的进行回答,而在问一些垂直领域的专业问题上,回答的结果往往差强人意。相较于开源公开的数据集,专业领域的知识数据很难获取,这也恰恰是企业的核心价值所在。所以,企业想要大模型性能与效果得到提升,就必须建立数据壁垒,提供足够多样化的高质量数据来满足模型训练的要求。
以数据为中心研发和训练大模型也已在行业内达成共识,我们希望未来有更多优质的大模型落地,赶紧用高质量的数据喂饱你的大模型吧!
如果您有训练大模型的困扰,欢迎电话咨询18518915150
上一篇
下一篇

 2023年08月23日
2023年08月23日



