











ChatGPT的出现证明,人类反馈强化学习(RLHF)训练可以大幅提升机器学习模型生成内容的范围、有效性和准确度。为了帮助更多用户进行高效的RLHF训练、打造优质的LLM训练数据集,倍赛科技推出RLHF文本标注功能。
4 月 21 日,复旦大学自然语言处理实验室发布的MOSS宣布开源,自 2 月份发布以来,MOSS 就承载着 NLP 爱好者对于“国产 ChatGPT”的强烈期待。MOSS 同样具有 ChatGPT 类似的文本生成、摘要、翻译等基础功能,但由于数据质量、计算资源和参数量等问题,距离 ChatGPT 的表现仍有差距。
MOSS 通过与人类和其他大语言模型交谈来学习,而 ChatGPT 的训练则是通过人类反馈强化学习(RLHF)来进行的 [1],在 GPT3.5 大规模语言模型的基础上, ChatGPT 依托大量有监督的文本标注数据,从而实现对人类指令的精准理解。通过在大数据预训练中增加人类反馈,并通过奖励模型使微调更加高效且有针对性,ChatGPT 生成内容的广度、有效性和准确性均得到显著提高。
倍赛科技开放RLHF多轮对话标注功能
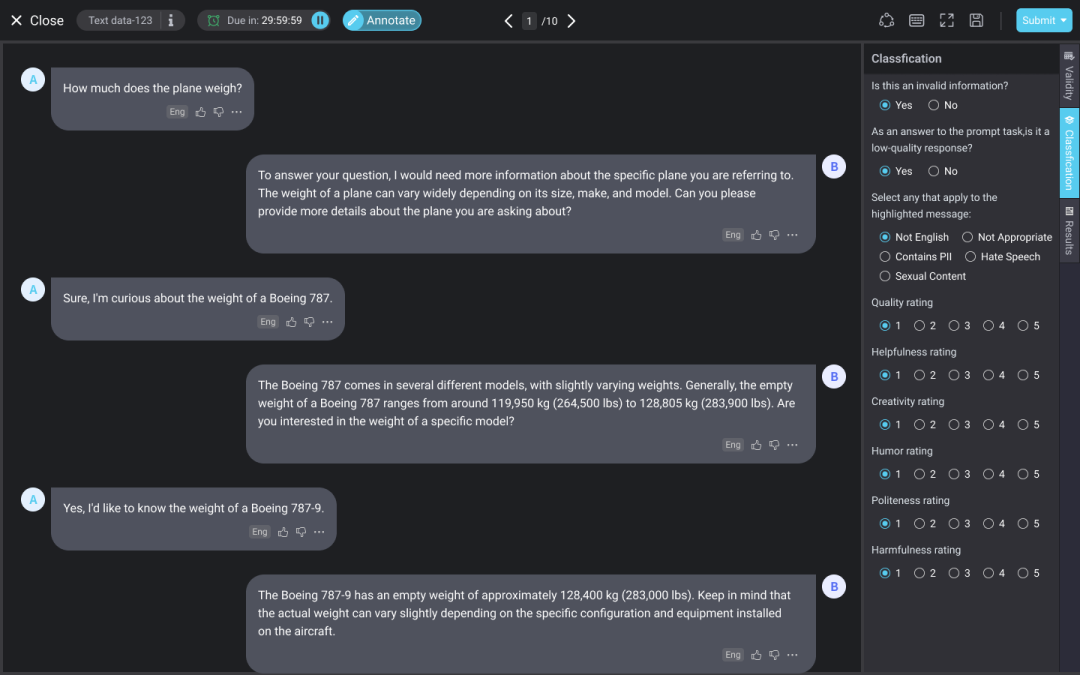
为支持用户进行有监督文本标注工作,实现大语言模型的训练,倍赛科技上线了支持 RLHF 训练的多轮对话标注工具集。
RLHF训练过程是怎样的?
对于 ChatGPT 的训练,InstructGPT 论文 [2] 中讲述了三个步骤:
1.收集由人类生成的高质量“提示词+回应(或 Instruction-Fulfillment)”样本;
2.讲样本随机显示给用户,让他们从最好到最差进行排序;
3.基于提示和奖励模型进行人类反馈强化学习(RLHF)训练阶段。
在 RLHF 阶段中,人类可以对答案进行排序、修改,或者针对上轮对话给出下轮的指令等,这样的反馈可以视为一种奖励信号,人工智能通过找到最能解释人类判断的奖励函数,使用 RL 来学习如何实现目标,逐步完善对目标的理解,建立任务目标模型。整个训练过程可以理解为“人类”、“AI 代理对于目标的理解”与“RL 训练”的三步循环 [3]。

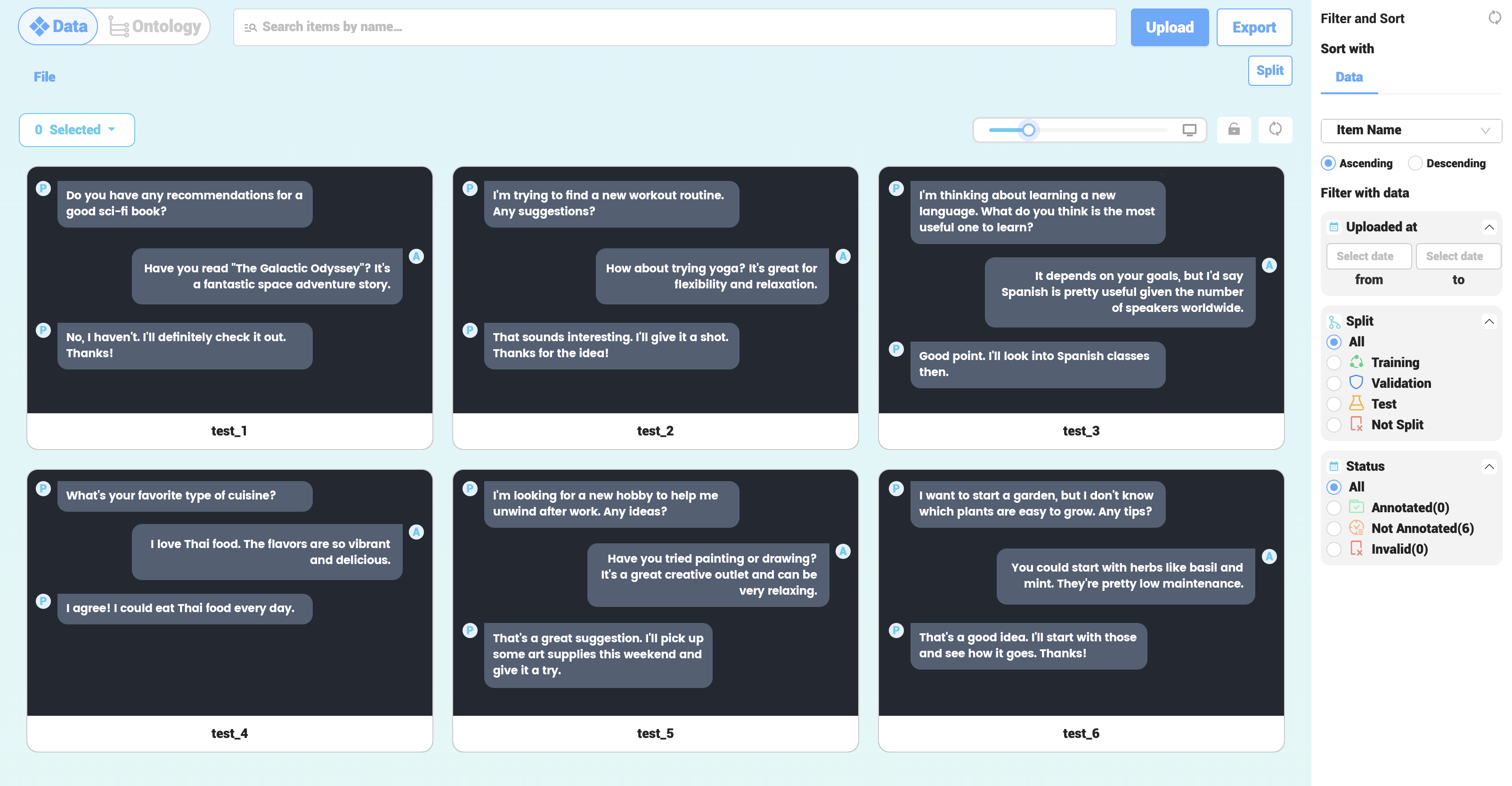
依照上述步骤,Open Assistant推出了数据收集任务平台,邀请用户扮演 AI 和用户(提示词工程师)完成相应的任务,帮助其建立一套自然的对话数据集,从而训练一个类 ChatGPT 的聊天 LLM。从平台面板中可以看到,Open Assistant 的训练需要人类完成“对 AI 的回复进行分类”、“对提示词工程师的回复进行分类”、“扮演 AI 来提供回复”、“扮演用户来提供回复”、“对 AI 的回复进行打分”等一系列任务。国内的智源研究院也推出了“OpenLabel 数据飞轮”公益项目,招募志愿者来打造开源数据集,类似地,OpenLabel 的任务类型包括“写出用户指令”、“作为 AI 助手回答”与“为 AI 助手判定答案”等。
上一篇
下一篇
 2023年05月26日
2023年05月26日



