











大模型数据服务
行业领先的大模型数据服务商倍赛科技,提供从开源到闭源,从清洗到蒸馏,从RLHF对齐到数据任务标注的一站式数据解决方案。帮助大型语言模型(LLM)实现高效的训练、微调和定制化,赋能千行百业的智能升级。
企业
业务数据
开源数据集
闭源数据集
数据是大型语言模型训练的核心
数据集是训练和优化大模型的基础,如果企业需要构建自己的大模型,没有足够的数据就难以打造出卓越的模型,而数据不仅要有开源的公共数据,更需要闭源的专业数据,例如企业内部的私有知识库,只有这些闭源专业数据才能让大模型进行有效的微调和满足企业的个性化需求。
解决方案

数据清洗
面向开源数据的清洗和结构化

信息提取
面向闭源数据的采集、信息提取及蒸馏

数据标注
面向大模型数据任务的标注平台及工具

RLHF
模型与人类意图对齐

模型调优
性能评估及模型优化

客户支持
帮助企业构建定制化大模型
数据展示
200TB+
开源数据集

10000+
SFT指令集
10亿+
Tokens

300万+
RHLF记录

100+
多模态数据集

500万册+
图书蒸馏数据集
大语言模型应用
 文本理解与创作
文本理解与创作 知识问答
知识问答 智能客服机器人
智能客服机器人 智能驾驶&智能座舱
智能驾驶&智能座舱 文生图
文生图 智慧医疗
智慧医疗 金融与法律
金融与法律 教育与学术研究
教育与学术研究 财务数据分析
财务数据分析 代码理解与编写
代码理解与编写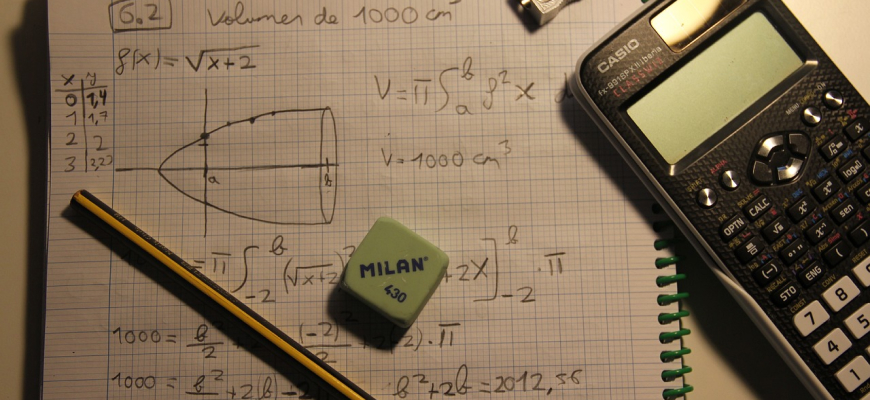 数学题解答 ......
数学题解答 ......典型案例

RLHF

基于人类反馈的强化学习,让大模型更好地符合人类的价值观和偏好,提高模型的准确性和泛化能力。
思维链构建

思维链构建是一种利用LLM进行推理的方法,它通过在输入中添加一些中间步骤来引导模型分解复杂的问题,并提供一个可解释的思考过程。以此来提高大模型的推理能力。

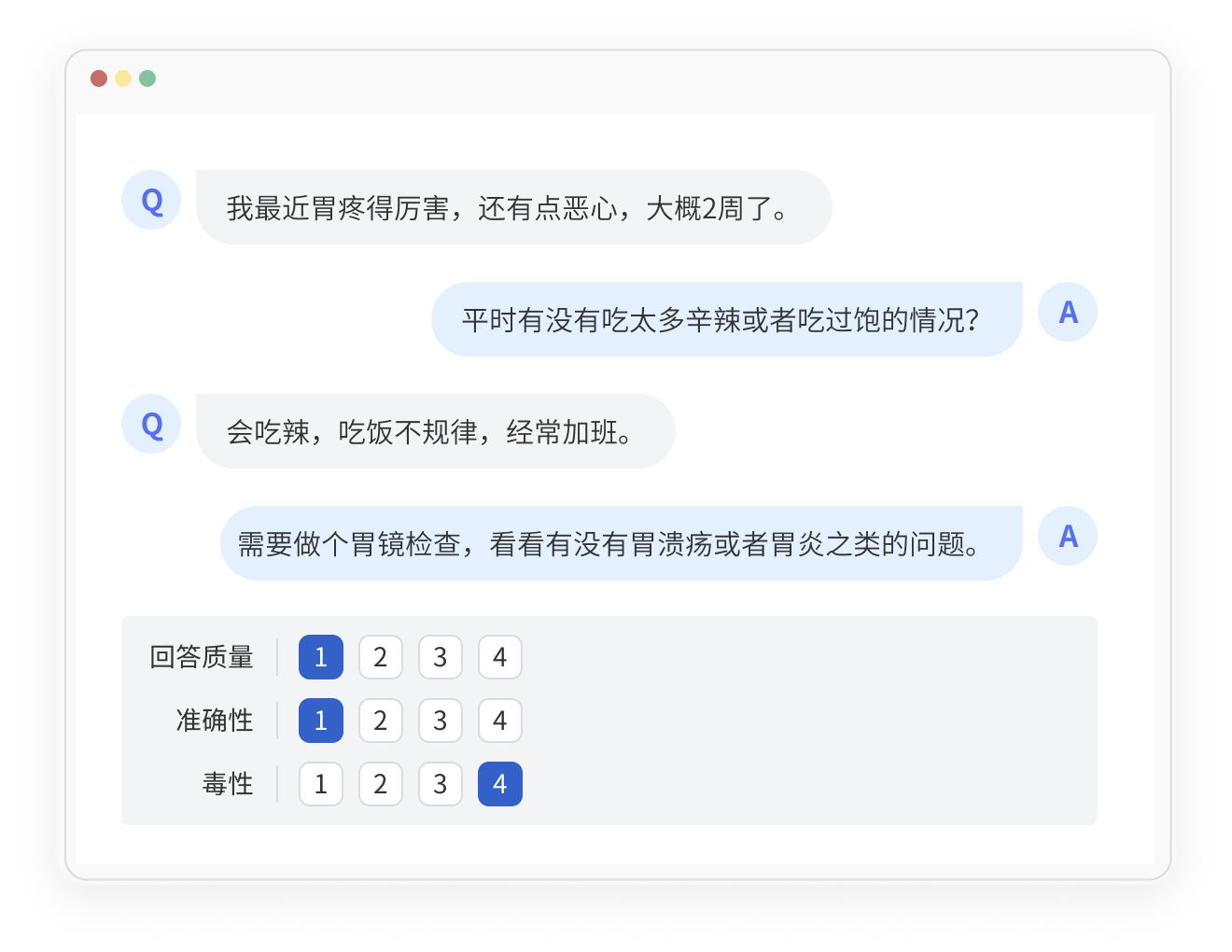
对话评估

多维度和指标来衡量对话的质量和效果。

使模型不断进行优化和改进,提升其在对话任务上的表现。
模型微调

根据客户不同的需求和场景,配置专业性强且高素质的人工智能训练师,确保输出高质量数据。
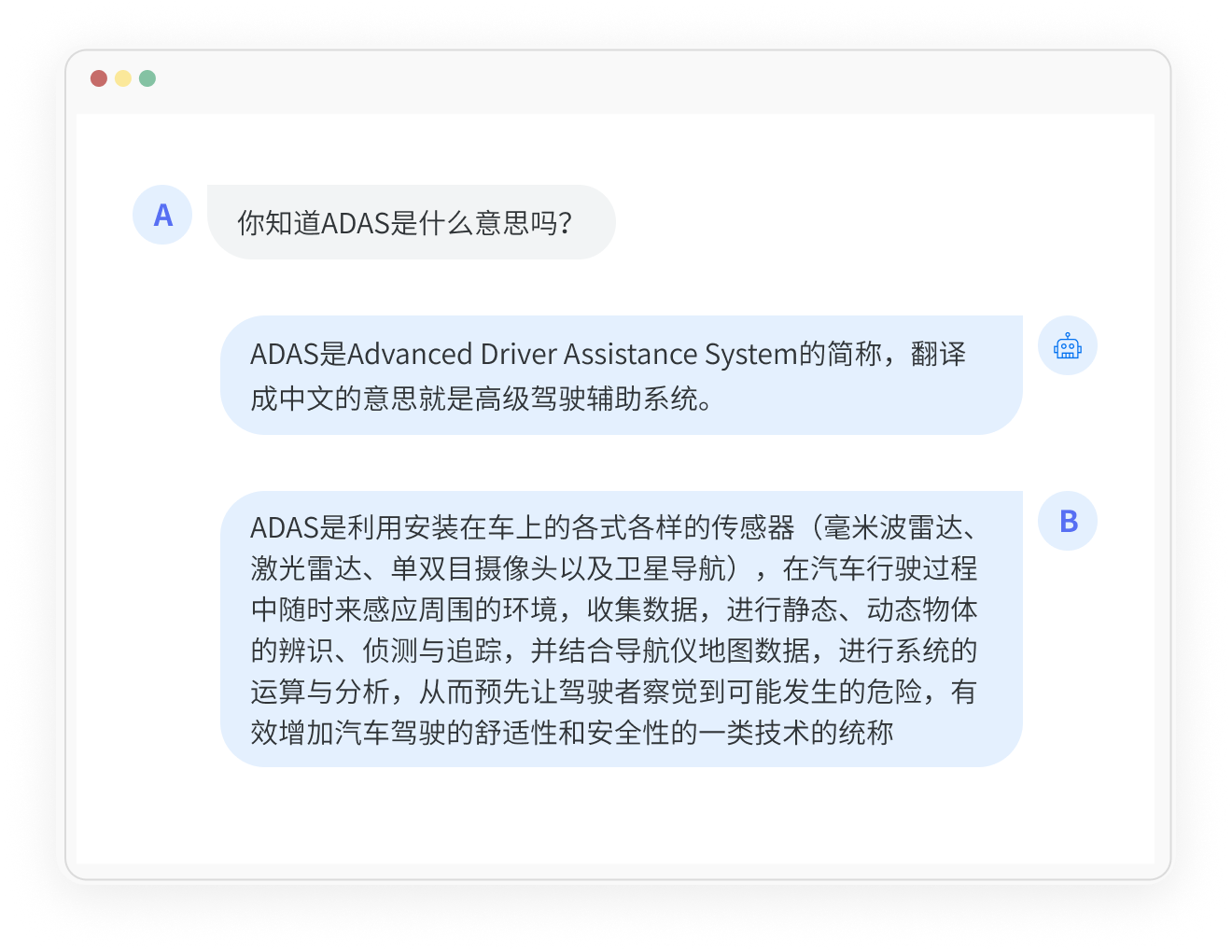
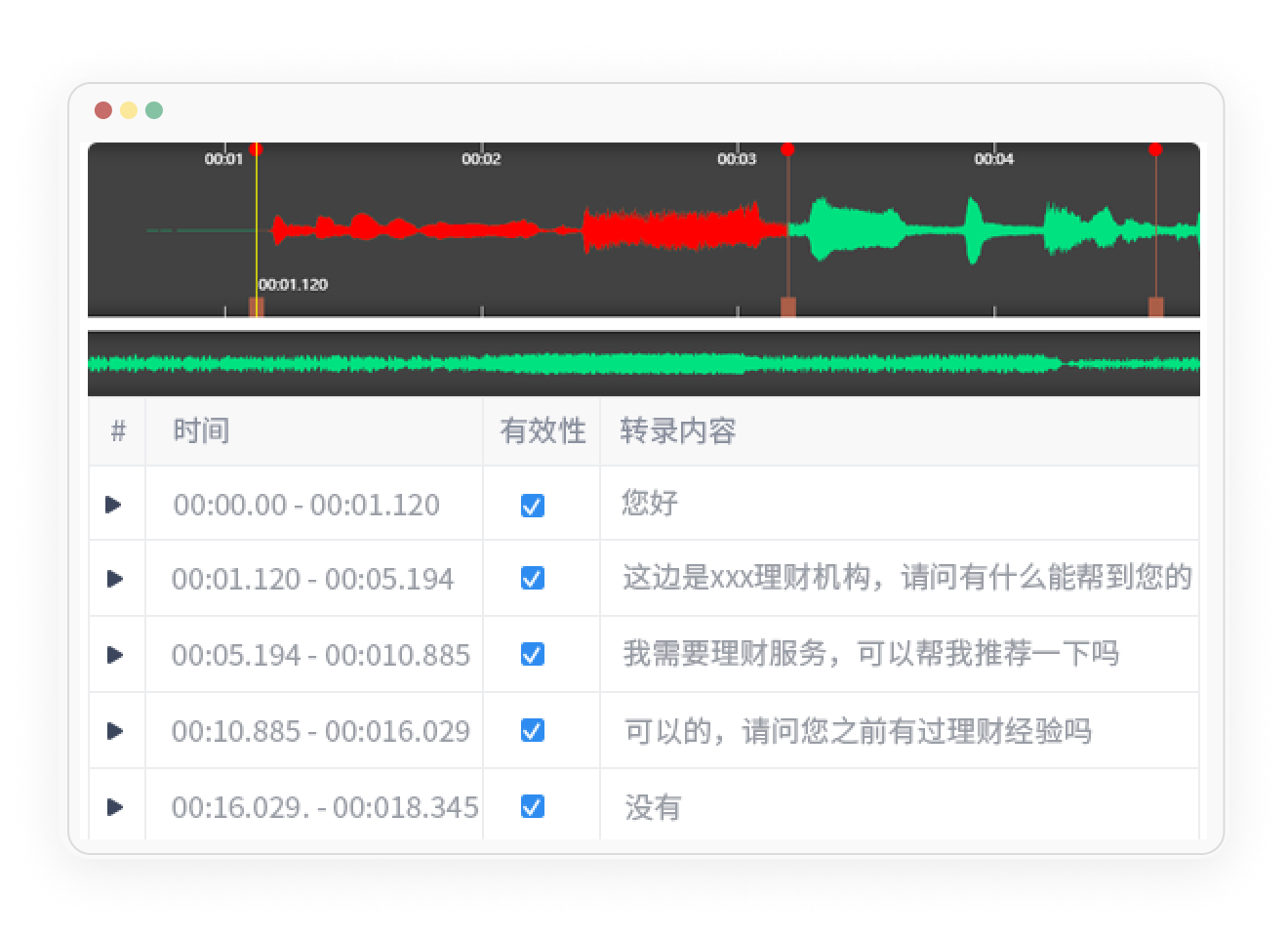
多模态标注

支持文本、音频、图像、视频及混合模态的数据类型,助力多模态大模型发展。

实现跨模态的理解、生成和检索等任务,提供更丰富和多样的服务和应用。
知识提取

从大量的非结构化和半结构化的数据中,抽取有意义的实体、属性、关系等信息,形成结构化的知识表示。

使模型能够更好地理解和处理复杂的任务和问题。
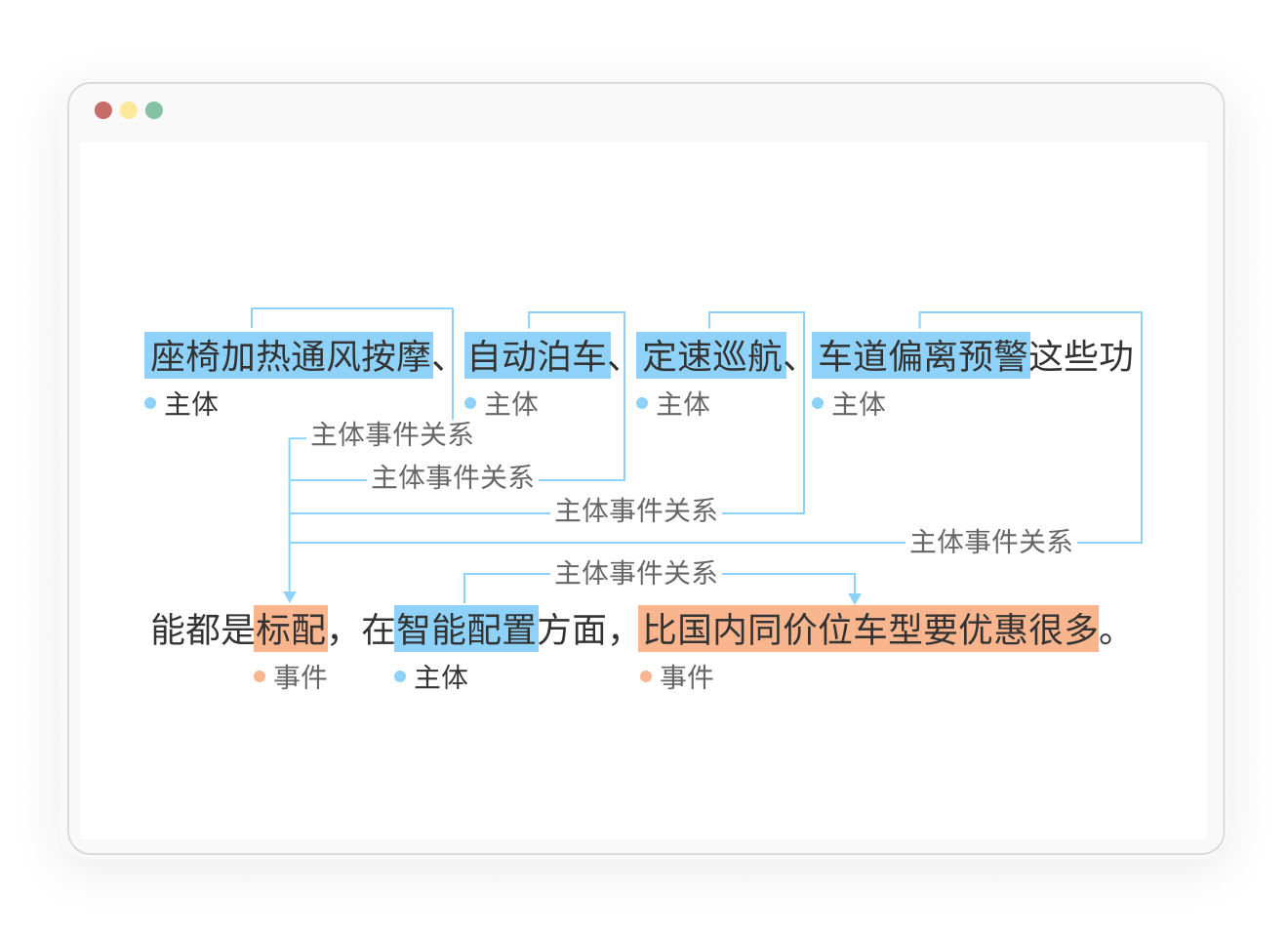
方案优势

一站式服务
我们提供训练数据工程化和训练数据生命周期管理服务,涵盖数据采集、清洗、标注、数据集管理以及模型建立、调优、部署和应用程序构造等环节。

数据质量高
我们使用先进的AI数据处理技术,保证数据的准确性、完整性和一致性,助力开发者高效获取AI开发所需高质量数据。

数据安全可靠
我们使用严格的数据安全和合规措施,保证数据的隐私和安全,避免数据泄露和滥用。

数据服务专业
我们拥有专业的数据服务团队,提供定制化的数据服务方案,满足用户多元场景的复杂需求。
倍赛科技是全栈AI数据及模型解决方案供应商,围绕数
据采集、数据清洗、数据标注、数据集管理、模型建
立、模型部署、应用程序构造等环节实现训练数据工程
化和训练数据全生命周期管理。

扫码关注倍赛官方公众号
联系我们
- 企业总机:
 185 1891 5150
185 1891 5150
- 北京总部:
 北京市海淀区群英科技园3号楼2层
北京市海淀区群英科技园3号楼2层